Faculty and Staff Contributers // Clemson University
Carl Ehrett, PhD, Troy Nunamaker, Hudson Smith, PhD
Student Contributers // Clemson University
Daniel Smith, Daphne Cottle, Manu Kolluru, Jeremy Mikale Crosby, Martin Scott Driggers, Mary Alice Schultz
Abstract
Background: Leadership is a career competency that is crucial for employability. Previous research has demonstrated that employers and students define leadership in different ways. This difference may constitute a competency gap that is detrimental to student success.
Purpose: The analysis of the language that employers and students use to describe leadership is a useful approach for understanding this difference in perspective. However, this approach is limited by the quantity of text that researchers can feasibly directly analyze. Artificial intelligence and machine learning can be employed to address this limitation.
Methodology: This study demonstrates how a machine learning (ML) framework can be applied to extend researchers’ analysis of a small subset of a large supply of text data to the entire data set.
Findings: The study shows that the result is near human-level performance in labeling text data at a scale well beyond what researchers can achieve unaided.
Implications: This study revealed discrepancies in how mentors and students describe the competency, leadership. The more academicians, employers, policymakers, and recent college graduates can understand the similarities and differences in how we define career readiness, the quicker we can adjust, meet the workforce’s current and future needs, and move towards closing the competency gaps.
Introduction
Employability has been part of the college graduate fabric and language surrounding degrees-earned for centuries (Peck, 2017). Throughout the twentieth century, the terms soft skills and transferable skills were similarly used by educators and employers when describing college graduates’ employability. The expression career competencies moved to the forefront of the career readiness discussion in the twenty-first century (Human Resources-UNL, 2017, p. 1), but the specific characteristics of both categorizations did not change during that transition. Leadership, communication, critical thinking, teamwork, professional ethics, technical savviness, intercultural fluency, and career management (NACE, 2016) have been competency or soft skill characteristics sought by employers, taught by educators, and leveraged by students (Farrar, 1980). Referred to throughout this paper as career competencies, rating and defining these eight characteristics has also continued to create a bit of rift (Cassner-Lotto & Barrington, 2006). Centuries after Aristotle first complained of Socrates’s career competence a millennium ago, there still appears to be a gap in perceived college graduate performance by employers and students (Peck, 2017).
Of the eight previously listed competencies, a collaborative effort between the National Association of Colleges and Employers and the National Association of Student Personnel Administrators found leadership, communication, and ethics among the top three performance gaps for recent college graduates (NASPA, 2018). In other words, recent college graduates rate themselves higher in leadership, communication, and ethical competence than employers rate the graduates. Further exploring the gap for any one of these competencies could reduce the gap among all competencies. Nunamaker, Cawthon, and James’ (2020) qualitative study explored the language employers and students used to describe leadership and proposed that both groups define leadership differently. With the advent of artificial intelligence, there is now an opportunity to apply tools from that domain to distinguish “career competency” language. Dissected comments from college students’ and employers’ opens the door for computerized analysis of the personal nuances associated with each group’s word choice, phrasing, and overall language differences.
For example, if students view and experience leadership differently from employers, then programming machine learning tools to code those differences on a macro scale could help analyze those competency gaps. Peck’s (2017) critique that “a wide range of different competencies that are not always clearly defined” (p. 3) leads to confusion could also be minimized by intentionally breaking down the nuances of students’ and employer’s word choice, phrasing, and overall language differences. Ultimately, a better understanding of the narrative employers and students use to describe career readiness could offer educators and others a wholly new and unique set of tactics to address those competency gaps that have plagued the workforce for centuries. This study specifically looks at the competency, leadership.
Literature Review
There is no shortage of leadership lenses that career readiness or the internship experience can be viewed through (Marion and Gonzalez, 2014). However, the transactional and transformational approaches are common and popular theories that have received substantial attention in the contemporary leadership field (Strong, Wynn, Irby, & Lindner, 2013). They are also seen as opposing ends of a leadership spectrum, task-oriented traits versus relationship-oriented traits (Stone, Russell, & Patterson, 2004), making them well suited to study when looking at how mentors and student interns describe leadership development.
While comparing how transactional and transformational leadership traits impact learning levels, Strong et al. (2013) found that relationship-oriented, rather than task-oriented, leadership traits provide more of a draw to students. As previously stated, this study sought to determine whether there was a difference in the leadership traits expressed by interns and mentors. Transactional and transformational leadership are the two primary working definitions utilized throughout the study. A third leadership style, servant leadership, was considered a separate variable before being grouped with transformational leadership.
Transactional Leadership
A transactional leadership style relies on well-defined and consistent organizational roles (Diaz-Fernandez, Pasamar-Reyes, & Valle-Cabrera, 2017). Under a transactional approach, leaders are well situated to maintain an organization, following and enforcing established procedures and norms. Likewise, these leaders typically do not change an organization’s structure (Lievens et al., 1997) or incorporate new assumptions, values, or norms (Bass & Avolio, 1993). Focusing on results and relying on rewards and punishments to achieve organizational ends are conventional approaches employed by a transactional leader.
Bass & Avolio (1994) and Lievens et al. (1997) provided several keywords that proved useful in conceptualizing transactional leadership for this study. These keywords were (a) reward, (b) goal, (c) incentive, (d) compensate, (e) outcome, (f) punish, (g) discipline, (h) reprimand, and (i) chastise.
Transformational Leadership
Transformational leaders, on the other hand, are often described as agents of change. They realign the organization’s culture to keep pace with evolving industry practices and developing markets (Bryman, 1996) by revising the organization’s shared values and norms (Bass & Avolio, 1993). The main factors that are hallmarks of transformational leadership are (a) charisma, (b) inspiration, (c) intellectual stimulation, and (d) individual consideration (Lievens et al., 1997; Humphreys 2005). These four factors were relied heavily on throughout the transformational leadership coding process in this study.
Servant Leadership as a Subset of Transformational Leadership
While there exists a sizeable body of research supporting the theory that servant leadership is a unique leadership style, some scholars instead consider servant leadership a subset of transformational leadership. For example, Chin and Smith (2006) indicated that servant leadership traits align with many transformational leadership traits. The general definitions of the servant and transformational styles overlap in many areas, making it difficult to differentiate the two explicitly. According to Washington et al. (2014), “These researchers suggested that while servant leaders are transformational leaders, the reverse may not be true” (p. 21).
The question of servant leadership’s status as a unique leadership style falls beyond the scope of this research. While some scholars have provided several distinguishing features between servant and transformational leadership (Spears, 2004; Parolini, 2007), these discriminants were too narrow to realistically be implemented in this study. More research can certainly be done to uncover qualitative differences between students and mentors regarding servant leadership.
Narrative Analysis
Narrative analysis involves examining materials produced by individuals desiring to share a story (Squire, 2013). Constructing a narrative about a specific event or period of time requires one to look backward in time and tell a story; in telling a story, the narrator sees “in the movement of events episodes that are part of some larger whole” (De Fina and Georgakopoulou, 2015 p. 27). Examining how individuals describe a specific event or time frame provides researchers insight into the similarities and differences of the language people use and how those people interact with their world.
For this study, a final evaluation for the intern program at Clemson’s Center for Career and Professional Development asking students to score their proficiency level for each competency and then share experiences supporting each of these scores was used for analysis. Stated differently, students provide a narrative detailing a critical experience or experiences for each competency, including leadership. Mentors are also similarly asked to rate their interns on their strengths and weaknesses, followed by an open-ended question requesting examples and an explanation for the score. Leadership is one such competency the mentors and students were both asked to respond to. Because students and mentors respond to final evaluation questions with stories detailing the internship experience, narrative analysis is a useful tool for examining qualitative differences in competency conceptualization in the career-readiness gap.
Applications for machine learning are continually increasing in popularity within the social sciences, specifically for the analysis of qualitative data (Chen, Drouhard, Kocielnik, Suh, and Aragon, 2018).
Although machine learning cannot perform at a higher degree of accuracy than a trained researcher, it stands to significantly increase the scale and efficiency of researchers’ analyses by enabling the analysis of vast datasets in a fraction of the time it would take a human researcher. Qualitative analysis is commonly undertaken through qualitative coding. Qualitative coding is the often-painstaking process of assigning labels of interest to segments of text (Miles and Huberman, 1994). These labels are determined via the symbolic analysis of patterns and relationships among the dataset.
Many variations of qualitative coding methodologies exist, but they share similarities, including iterations of coding. Prevalent coding iterations include unrestricted coding, focused coding, axial coding, and theoretical coding. Each variation serves a distinct objective, but all aim towards the prevailing goal to ultimately gain a deeper understanding of the dataset.
Crowston, Allen, and Heckman (2012) apply natural language processing (NLP) techniques by automating the content analysis of individual and group responses, specifically the extraction of theoretical evidence from texts. This approach aims to increase efficiency and reduce human manual effort in coding. Additionally, applying NLP to qualitative data increases the volume of data that can be processed and does so at a higher inter-rater reliability (consistency, rather than accuracy/precision) than manual human analysis. Furthermore, this study addresses the concern of sensitivity and agreement of multiple persons qualitative analysis, due to varying perspectives and interpretations. This study performed by Crowston, Allen, and Heckman is significant as it is among the first to apply higher-level NLP techniques in assessing qualitative data. While their study takes a different approach to using NLP on qualitative data than this study, many similarities can be observed between the two studies. Both studies possess common goals of reducing the manual effort required by humans in coding, allowing for the analysis of larger datasets than would otherwise be feasible, as well as the goal of improving labeling consistency.
Another study, conducted by Colley and Neal (2012), highlights the use of machine learning to conduct qualitative analysis by algorithmically parsing through qualitative data and visually expressing the findings. Although Colley and Neal’s study was conducted differently from how the present study was conducted, similarities between the aims of both projects include: (a) the use of artificial intelligence (AI) to visually express the disconnect between different groups/differing levels of seniority, (b) the usefulness of AI in qualitative research to reduce the subjectivity of the research, and (c) deliver an analysis that can be used to close the communication gap between collaborative groups.
Methodology
Data
The data for this project was obtained through Clemson University’s Center for Career and Professional Development. The Center for Career and Professional Development serves almost 25,000 students spanning the university’s seven colleges. Any intern that has completed an internship through the Center’s internship course was required to complete a final evaluation focusing on competency development as part of the curriculum. This course included students from varying majors and class standings. Along with the interns, their mentors also completed the survey about students’ competencies following the internship. For this study, all the student responses were cleansed of personal information and used in the dataset. Also, the responses from mentors who rated students with the highest and lowest leadership scores were cleansed of personal information and used in the dataset. Out of these 6155 responses, 5088 were student responses, and 1067 were mentor responses.
Manual Coding and Labeling: Segment Responses by Sentence
To build the dataset, the student and mentor responses were chunked into sentences. Chunking the paragraphs into sentences allowed for triple the data. The practice also had the effect of removing the rest of the paragraph’s context, thereby removing noise from the rest of the paragraph, as for example when a subject mixes both types of leadership language in separate sentences of the same paragraph. In contrast, an individual sentence can be easier to isolate into types. Sentences were initially grouped into the categories: none, transactional, somewhat transactional, uncertain, somewhat transformation, transformational (see Table 1).
Dividing the responses down into smaller chunks than each sentence was considered at the beginning of the study. However, single sentences were ultimately deemed the lowest level of chunking for each response. At this level, chunking allowed for a complete thought while not overwhelming each response with too much data (since document embedding can more easily capture the meaning of short passages than of long ones) or noise (since some subjects used multiple types of leadership language).
Table 1
Examples From the dataset
| Label | Description | Example |
| None | The sentence uses no leadership language | She is poised, fun to be around and really understands the work she is doing |
| Transactional | The language of the sentence clearly aligns with Transactional leadership | I also created a task list of when specific things were due to help complete things as efficiently as possible and to remove as much stress as possible |
| Somewhat Transactional | The language of the sentence does not directly show Transactional leadership, but it is more so transactional than Transformational | Emily has always been a leader but this year grew in this area even more so being our most senior intern and serving as an example and guide to our other 4 interns |
| Uncertain | The sentence contains language that represents both leadership theories | Jackson was able to lead a team of a dozen student hourly workers to maintain a safe and accessible environment for students of all backgrounds to learn machine tool practices |
| Somewhat Transformational | The language of the sentence does not directly show Transactional leadership, but it is more so transactional than Transformational. | From the beginning when I first joined the team at Madren Center, the supervisors encourage all of us to look towards our goal for the end of the semester |
| Transformational | The language of the sentence clearly aligns with Transformational leadership | I was able to get the whole office behind me on this mission and get them involved to the point where they felt invested in the process as well |
Labeling Consensus and Confidence Score
An online labeling tool called Labelbox was used to code the sentences in the dataset (Labelbox), which allowed for a summary of the labeling results to be downloaded for the study. The download included information about the chosen label for each sentence and the researcher who chose that label.
Additionally, to reduce individual bias during the labeling process, some sentences needed to be labeled by more than one researcher. This step was implemented through Labelbox’s Consensus feature, which consists of two measures. The first measure is Coverage, which is the percentage of the dataset randomly selected to receive labels from multiple researchers. This study leveraged a Coverage of 40 percent, in order to balance the need to assess inter-labeler reliability with the need to maximize the amount of data produced by the labelers’ efforts. The second measure is Votes, or how many labels are required for each sentence comprising multiple labels. With three to five labelers available each semester, three Votes were chosen in this study. This number was robust to fluctuations in the number of available labelers, and, being odd, helped reduce the occurrence of tie votes.
For sentences labeled by a single researcher, the researcher’s label was chosen as the proper label for that sentence. When multiple labelers labeled a sentence and there was a majority agreement, the majority choice was chosen as the proper label. Lastly, if no majority choice existed amongst the labeling researchers, the label corresponding to the labeler (or labelers) with the most authority on the subject was chosen. Authority was based on expertise and experience with the subject matter, the highest authority going to the researcher pursuing a terminal degree in educational leadership while serving as a full-time career counselor in career services, and the lowest authority going to the newest researcher member with no previous semesters working on the study.
Training and Cleaning Data
Upon finishing the data labeling, the data was cleaned before applying a machine learning model to it. Cleaning textual data involved removing duplicate entries, discarding empty sentences, and preprocessing the text as described below. The dataset contained ten duplicate entries and eight empty sentences. After investigating the duplicates, some entries were discovered to be the result of mentors copying and pasting responses for multiple interns, sometimes across semesters. Excluding one sentence, when duplicates showcased the same labels, the duplicates’ first instance was kept.
Text preprocessing has been shown to improve model performance in text categorization (Camacho-Collados & Pilehvar, 2017). It involves simplifying and standardizing the vocabulary of words input into the machine learning model. As an example, consider the preprocessing task of lowercasing letters. The two words “Leader” and “leader” are the same word, but their capitalization is different, so the machine learning model sees them as separate words. However, training the machine learning model to see the two words as the same is the desired result. Adjusting the two words to the lowercase word, “leader,” allows the model to recognize them as the same word and prevents categorization inconsistencies. In addition to changing to lowercase, characters not found in the alphabet were also eliminated from the data. Examples of these characters include numbers, punctuation, and special characters.
Another text preprocessing technique considered but ultimately dropped was stemming. Stemming involves reducing a word to its root or simplest form. For example, the words “inspire,” “inspired,” and “inspiring” could be reduced to the root “inspir.” The goal behind stemming is to simplify the vocabulary words even further before feeding them into the machine learning model. However, this technique was abandoned because experimental results indicated only very marginal improvements (if at all) to classification.
Model Predictors
To apply a machine learning method to the text, it must be converted into a numeric representation. A common technique for this is the so-called “Bag of Words” (BoW) approach. For this technique, each sentence is encoded as a vector of length v, where v is the total number of distinct words appearing in the corpus. Each vector element is a one if the corresponding word appears in the sentence and zero otherwise. BoW has the drawback of failing to preserve semantic or contextual relationships between words. For example, under BoW, the encodings for “lead” and “guide” would be entirely independent, despite their similar meanings and appearance in similar contexts. For this reason, Word2Vec (W2V) embedding was used instead (Mikolov et al., 2013). Under W2V, each word in the corpus is given a representation in a k-dimensional vector (for user choice of k; we used k=30). The representation of each word is learned from the corpus, with the intention that the representations of words appearing in similar contexts will have similar vector encodings. Thus, in contrast with BoW, “lead” and “guide” should be represented by vectors that are numerically close to one another. To affect the W2V embedding, the open-source fastText library is relied on (Joulin et al., 2016; Bojanowski et al., 2017).
Model Response
The model for this study has k-dimensional numeric input and one-dimensional output. The model’s output is a category determination, corresponding to the categories used by the human labelers. For the version of the analysis with the six labels of Table 1, there are six possible outputs. Likewise, there are three possible outputs of the model for the binned version of the analysis.
Running the Model and Model Choice
The statistical model used in this study is logistic regression. Logistic regression is a statistical classification method widely used in machine learning algorithms due to its simplicity and interpretable nature.
Selecting Best Model
L2 regularization of the model parameters was used to improve the model’s generalizability in this study. Also known as ridge regression or Tikhonov regularization, this regularization requires specifying a penalty on the L2 norm of the model parameters. Estimating the F1 score, repeated stratified k-fold cross-validation was employed (with ten repetitions of k=5 folds) to find the optimal penalty value and the optimal model specification. It was found that a penalty of approximately 1/1.87 results in the best model fit for the application. The resulting model was then paired to a training set of two-thirds of the total data set. This process helped to evaluate performance against a test set composed of the remaining one-third data set.
Results
The model significantly decreases the amount of time spent deciding the final label for each sentence. Over 16 months, 85 hours were spent labeling sentences through Labelbox. The logistic regression model script, including the completion of 10-fold cross-validation before fitting the final model, runs in under 5 minutes. Once the model is fit to the data, new responses can be labeled in seconds.
Below are some of the metrics used to evaluate the logistic regression model (see Table 2).
- Precision – the percentage of labels that were correctly identified by the model. The higher the precision, the more likely the model is correctly able to predict the type of leadership used in the sentence. It is calculated as TP/(TP+FP), where TP is the number of true positives (i.e., correctly labeled instances of a category) and FP is the number of false positives (i.e., sentences incorrectly labeled as belonging to a category).
- Recall – the number of correct positive predictions made out of all positive predictions that could have been made. It is calculated as TP/(TP+FN), where FN is the number of false negatives (i.e., sentences incorrectly labelled as not belonging to a category).
- F1 Score – the harmonic mean of precision and recall. It is calculated as 2PR/(P+R), where P is precision and R is recall.
- ROC-AUC – Receiver operating characteristic (ROC) is constructed by plotting the true positive rate versus the false positive rate. The area under the curve (AUC) represents how much the model is able to distinguish between the classes. The higher the AUC, the better the model is at classifying labels (see Figure 1).
- Precision-Recall Curve – constructed by plotting the precision versus recall of the model. The area under the curve represents the proportion of time the model is predicting the labels correctly (see Figure 2).
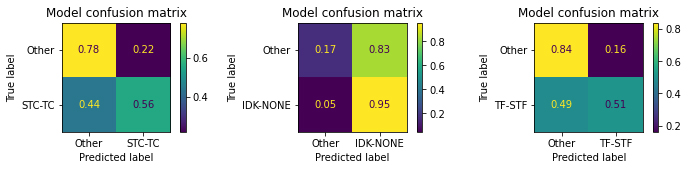
- Confusion Matrix – shows the relationship between the true labels and the predicted labels (see Figure 3).
- Support – is the number of labels in each category of leadership style.
Table 2
Performance metrics for the logistic regression model
| Class | Precision | Recall | F1 | Support |
| TC/STC | 0.29 | 0.68 | 0.41 | 315 |
| NA/IDK | 0.70 | 0.95 | 0.81 | 1371 |
| TF/STF | 0.45 | 0.47 | 0.46 | 364 |
Figure 1
ROC Curve
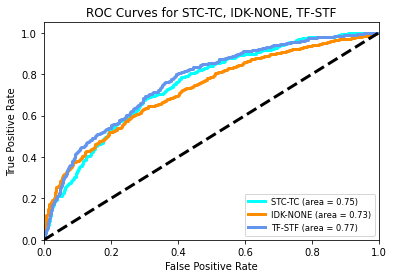 1
1
Figure 2
Precision Recall Curve
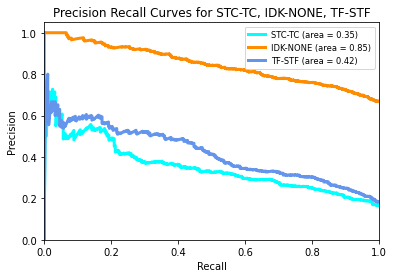
Figure 3
Confusion matrices for the model’s results
Scores
Identifying the leadership style reflected in a short text document is a difficult task even for humans. To assess the utility of machine learning approaches to this task, it is therefore not sufficient to consider the model performance in isolation, but rather to compare its performance to that of the human labelers. In Table 3, we provide such a comparison. There, we calculate average F1 scores for the human labelers. For each human labeler, we found his or her F1 score using the documents that were labelled by multiple labelers, treating the others’ labels as the ground truth against which to assess each individual. As we see in Table 3, the model’s performance is very close to that of the human labelers in the set of binary tasks of determining whether each of the three labels applies to a text document. There is a large class imbalance in the NA-IDK category (see Figure 4). Labelers chose the NA-IDK category when it was unclear which leadership category to best fit the data (I Don’t Know), or they found the data to be not applicable (Not Applicable) to any of the provided categories. Nonetheless, it is still seen that leadership language has been identified more within student responses than within mentor responses. Also, language speaking to transformational leadership was identified more than transactional in both mentor and student responses.
Table 3
Human Labeler F1-Score vs Model F1-Score
| Class | Labeler F1 Score | Model F1 Score |
| TC/STC | 0.44 | 0.41 |
| NA/IDK | 0.82 | 0.81 |
| TF/STF | 0.50 | 0.46 |
Figure 4
Mentor vs student proportions
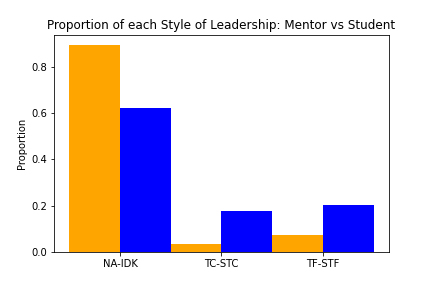
Note. Labels for mentor responses (orange) are proportionally higher in the NA-IDK category, while labels for student responses (blue) are proportionally higher in leadership categories.
Conclusion
The difference in language used to describe leadership among employers and students ultimately results in discordance in leadership evaluation. This discordance is not limited to leadership, but it also extends to various career competencies desired by employers, such as communication, critical thinking, teamwork, professional ethics, technical savviness, intercultural fluency, and career management (NACE, 2016). This competency gap significantly impacts students’ success and employability. However, as seen by the results in this study, the competency gap can be analyzed by applying ML frameworks to aid in large scale text analysis, previously infeasible by researchers. ML frameworks result in near-human level performance with increased efficiency and consistency by analyzing large quantities of text data.
Summarizing the Results
The repeated k-fold cross-validation used to tune the model requires 2.5 minutes to complete, on the free Google Colab computation platform. This process involves fitting 50 logistic regression models; fitting any one model, including the final model, takes only seconds. Our final model was fitted on a training set of two thirds of the full human-labeled data (4105 documents). Generating predictions for the complementary test set (of size 2050 documents) required around three thousandths of a second. Thus, once fitted, the model can be used to provide labels for new data essentially instantaneously. This stands in stark contrast to the very laborious process of manually labeling the data, wherein the labeled data set required around 85 hours of human labor. As seen in Table 3, evaluation of the model on the test set shows that it achieves very near human-level results on each binary task of deciding whether one of the labels does or does not apply.
The model is less reliable on the more difficult task of deciding which one of the three labels best applies to a document, due to the large class imbalance in favor of NA/IDK cases. Thus, for optimal reliability, the model is better deployed on the binary task. This is also reflected in the confusion matrices of Figure 3, in which one can observe the model’s preference for that label.
Implications and Future Research
Mentioned earlier in this article, although machine learning cannot perform at a higher degree of accuracy than a trained researcher, it stands to significantly increase the scale and efficiency of researchers’ analyses by enabling the analysis of vast datasets in a fraction of the time it would take a human researcher. Continuing to work towards removing the human bias from the technology, whether conscious or unconscious, remains a challenge for those working in the field.
Nevertheless, students appear to use transactional and transformational language at a higher rate than mentors, which can explain part of the competency gap. However, a large portion of the codes fell into the NA or IDK categories, which points to either mentors and students not using leadership language to describe leadership experiences or mentors and students using leadership language from a tertiary theory. For example, the leadership identity development theory (Komives, Casper, Longerbeam, Mainella, & Osteen, 2004) is one model that might align with the mentors’ view of leadership. Themes like confidence, self-awareness, initiative, and exploration or development appeared to be present in the mentor’s comments and those characteristics are also present in leadership development theory.
Also, using natural language processing to explore the other career competencies is a natural progression and the next step in the research. Many social science disciplines rely heavily on qualitative methods for analyses that are not easily undertaken using quantitative data, and this has insulated the social sciences from some of the benefits other fields have derived from ML (Chen et al. 2018). The proposed methodology may help to close that gap between qualitative social science research and ML. Further applications of AI and ML frameworks to explore common competency gaps is a reasonable next step.
Communication, critical thinking, teamwork, professional ethics, technical savviness, intercultural fluency, and career management (NACE, 2016) might appear to be well-defined competencies on the surface. However, this study has already revealed discrepancies in how mentors and students describe the competency, leadership. The more academicians, employers, policymakers, and recent college graduates can understand the similarities and differences in how we define career readiness, the quicker we can adjust, meet the workforce’s current and future needs, and move towards closing the competency gaps.
References
Bass, B., & Avolio, B. (1993). Transformational leadership and organizational culture. Public Administration Quarterly, 112-121.
Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5, 135-146.
Bryman, A. (1996). Leadership in organizations. Handbook of Organization Studies, 276, 292.
Camacho-Collados, J., & Pilehvar, M. T. (2017). On the role of text preprocessing in neural network architectures: An evaluation study on text categorization and sentiment analysis. arXiv preprint arXiv:1707.01780.
Cassner-Lotto, J., & Barrington, L. (2006). Are they really ready to work? Employers’ perspectives on the basic knowledge and applied skills of new entrants to the 21st century US workforce. Washington, DC: Partnerships for 21st Century Skills.
Chin, D., & Smith, W. (2006). An inductive model of servant leadership: The considered difference to transformational and charismatic leadership. Monash University Department of Management.
Colley, S., & Neal, A. (2012). Automated text analysis to examine qualitative differences in safety schema among upper managers, supervisors and workers. Safety Science, vol. 50, no. 9, pp. 1775–1785., doi:10.1016/j.ssci.2012.04.006.
Crowston, K., Allen, E., & Heckman, R. (2012). Using natural language processing technology for qualitative data analysis. International Journal of Social Research Methodology, 15:6, 523-543, DOI: 10.1080/13645579.2011.625764
De Fina, A., & Georgakopoulou, A. (2015). The handbook of narrative analysis. West Sussex, UK: Wiley Blackwell.
Diaz-Fernandez, M., Pasamar-Reyes, S., & Valle-Cabrera, R. (2017). Human capital and human resource management to achieve ambidextrous learning: A structural perspective. BRQ Business Research Quarterly, 20(1), 63-77.
Farrar, E. (1980) The Walls Within: Work, Experience, and School Reform. Cambridge, MA: Huron Institute.
Human Resources-UNL. (2017). The definition of competencies and their application at NU. University of Nebraska.
Humphreys, J. (2005). Contextual implications for transformational and servant leadership: A historical investigation. Management Decision, 43(10), 1410-1431.
Joulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2016). Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759.
Lievens, F., Van Geit, P., & Coetsier, P. (1997). Identification of transformational leadership qualities: An examination of potential bias. European Journal of Work and Organizational Psychology, 6(4), 415-439, doi: 10.1080/135943297399015
Marion, R. & Gonzalez, L. (2014). Leadership in education: Organizational theory for the practitioner (2nd ed.). Long Grove, IL: Waveland Press.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Chen, N. C., Drouhard, M., Kocielnik, R., Suh, J., & Aragon, C. R. (2018). Using machine learning to support qualitative coding in social science: Shifting the focus to ambiguity. ACM Transactions on Interactive Intelligent Systems (TiiS), 8(2), 1-20.
National Association of Colleges and Employers. (2016). Career readiness defined. Retrieved from http://www.naceweb.org/knowledge/career-readiness-competencies.aspx
NASPA. (2018). Are your students career ready? National Association of Student Personnel Administrators and the National Association of Colleges and Employers.
Nunamaker, T., Cawthon, T., and James, A. (2020). The leadership competency: How interns and employers view development. NACE Journal, May, 22-28.
Peck, A. (2017). Engagement and employability: Integrating career learning through cocurricular experiences in postsecondary education. Washington, DC: NASPA.
Parolini, J. (2007). Investigating the distinctions between transformational and servant leadership, 68(04), 1-95.
Spears, L. C., & Lawrence, M. (Eds.). (2016). Practicing servant-leadership: Succeeding through trust, bravery, and forgiveness. Hoboken, NJ: John Wiley & Sons.
Squire, C. (Academic). (2013). Narrative research: An interview with Corrine Squire [Streaming video]. Retrieved from SAGE Research Methods.
Stone, G., Russell, R., & Patterson, K. (2004). Transformational versus servant leadership: A difference in leadership focus. Leadership and Organization Development Journal, 24(4), 349-361. doi: 10.1108/01437730410538671
Strong, R., Wynn, J., Irby, T., & Lindner, J. (2013). The relationship between students’ leadership style and self-directed learning level. Journal of Agriculture Education, 54(2), 174-185. doi: 10.5032/jae.2013.02174
Washington, R., Sutton, C., & Sauser Jr, W. (2014). How distinct is servant leadership theory? Empirical comparisons with competing theories. Journal of Leadership, Accountability & Ethics, 11(1). 11-26.